


Kennt ihr das? Ihr seht eine wilde Zeichenkette voller Punkte, Sterne, Klammern und fragt euch: "Wer versteht sowas?" Genau das habe ich auch immer gedacht, wenn ich irgendwo unbeabsichtigt auf Regex gestoßen bin. Bis wir uns dann letzte Woche damit befasst haben. Und tatsächlich: Es ist gar nicht so kompliziert, wie es aussieht!
Was ist Regex eigentlich?
Regex (kurz für "Regular Expressions") ist eine Art Suchmuster, mit dem man Zeichrenfolgen nach bestimmten Regeln durchsuchen oder umformen kann. Es ist sich vorzustellen wie eine Suchfunktion, die aber nicht nur nach einzelnen Wörtern sucht, sondern auch nach Mustern. Es ist quasi eine universelle Sprache für die Textverarbeitung, die in vielen Programmiersprachen, Datenbanken und sogar in Texteditoren genutzt wird.
Um es zu veranschaulichen, nehmen wir uns ein Beispiel an Telefonnummern. Und zwar besteht die Absicht darin, in einem (eventuell sehr langen) Text alle Telefonnummern zu finden, die mit einer bestimmten Vorwahl beginnen. Mit Regex wird nur das gesuchte Muster definiert und alle, dem Muster entsprechende Nummern, gefunden.
Nehmen wir an, dass die gesuchte Vorwahl "0152" ist. Das Regex-Muster könnte wir folgt aussehen: "0152\d{8}".
Eine Regex besteht in der Regel aus einer Kombination von Zeichen, Sonderzeichen oder sogenannten Metazeichen, die bestimmten Regeln folgen.

Was oben definiert wurde, wäre übersetzt: "Suche diese vier Ziffern 0152 und gebe sie mir mit den folgenden acht Ziffern \d{8} wieder.
Es gibt auch meistens auch nie nur eine bestimmte Regex für ein gesuchtes Muster. Verschiedene Kombinationen, der eine komplizierter als der andere, können aber letztendlich zum selben Ergebnis führen.
Wofür braucht man das?
Regex wird in vielen Bereichen genutzt:
Datenanalyse & Bereinigung: Natürlich bieten Tableau / Tableau Prep oder Alteryx verschiedene Tools an, womit bestimmte Werte herausgefiltern, ersetzt oder einfach nur gefunden werden müssen. Aber vor allem wenn es sich zum Beispiel um eine riesige Tabelle oder einem sehr langen Text handelt, hilft Regex! Außerdem werden ohne Regex eventuell mehr Schritte erforderlich.
Web Scraping: Web Scraping ist eine Methode, um Daten zu extrahieren, insbesondere von Websites. Wer solche Quellcodes kennt, weiß wie lang diese sein können. Beim Web Scraping ist Regex definitiv der beste Freund!
Auch in der einfachen Textverarbeitung kann Regex Anwendung finden, wenn mit langen Dokumenten gearbeitet wird und bestimmte Passagen rausgezogen werden sollen.
Programmierung & Webdesign: Von Validierungen (z. B. "Ist das eine gültige E-Mail?") bis hin zu Suchfunktionen in Apps ist Regex überall im Einsatz.
Regex in Alteryx
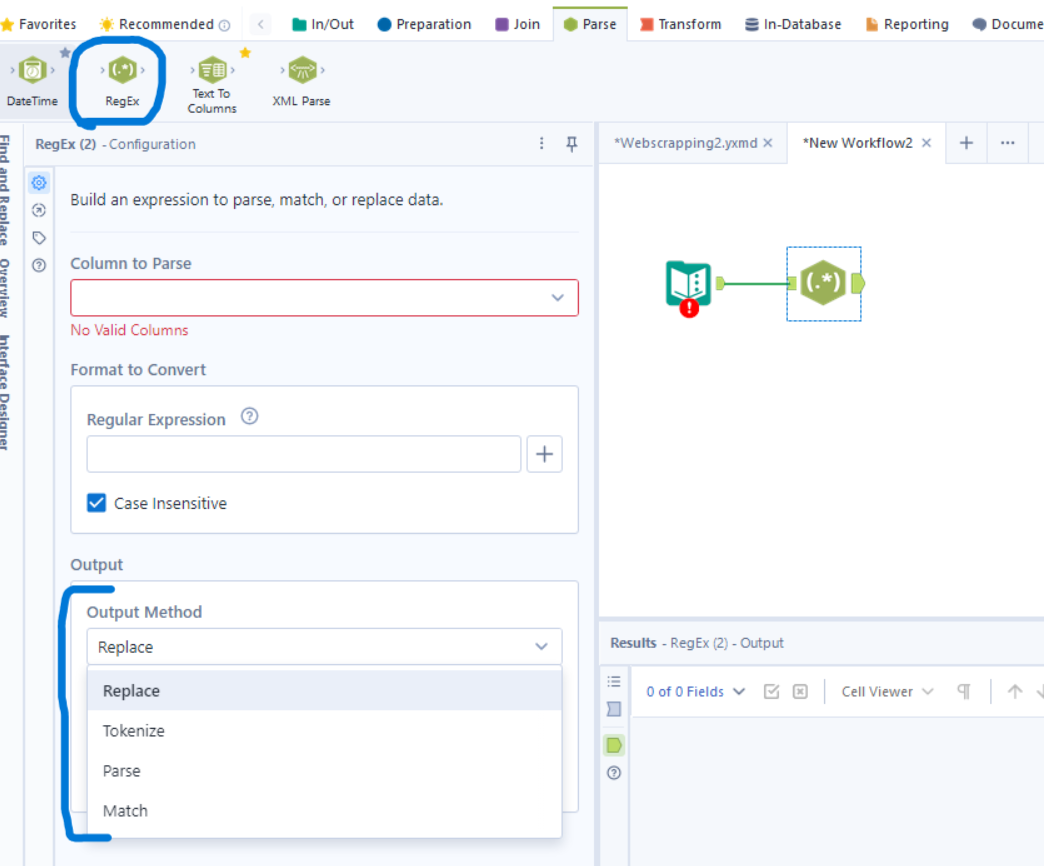
Alteryx bietet mehrere Möglichkeiten, Regex anzuwenden, um Daten zu analysieren oder umzuwandeln. Es gibt verschiedene Regex-Funktionen, die analog zu den traditionellen String-Funktionen sind.
- Parse: Mit der "Regex Parse"-Funktion können bestimmte Teile aus einem Textfeld extrahiert werden. Zum Beispiel könnte mit ([A-Z]\w+) alle Wörter extrahiert werden, die mit einem Großbuchstaben beginnen. Dabei wird das gesuchte Muster umklammert.
- Tokenize: Diese Methode hilft, Text anhand eines Musters in mehrere Teile zu zerlegen. Beispielsweise kann man eine lange Zeichenkette mit Leerzeichen oder Kommas aufsplitten, entweder in Spalten oder in Zeilen.
- Match: Hier wird geprüft, ob eine Zeichenkette einem bestimmten Muster entspricht. Nützlich, um z. B. nur Zeilen zu behalten, die einer bestimmten Struktur entsprechen. Hierbei könnte es sich um eine E-Mail handeln. Das Ergebnis, was Alteryx wiedergibt, ist dann ein TRUE/FALSE.
- Replace: Mit der "Regex Replace"-Funktion können gezielt Zeichenfolgen in einem Text ersetzt werden. Angenommen, in einer Liste von Telefonnummern sollen alle Bindestriche durch Leerzeichen ersetzt werden, dann könnte das Muster - mit dem definierten Ersetzungswert ersetzt werden.
Eine sehr häufig verwendete Regex ist ".+?". Dieses Muster beschreibt übersetzt, dass es jedes beliebige Zeichen betrachten soll ".", welches mindestens einmal vorkommt "+".
Das Fragezeichen macht deutlich, dass das Muster aber ein Ende hat. Da das Plus keine eindeutige Menge definiert, könnte das Muster auch unendlich lang gehen. Je nach dem also, wie der Text ausschaut, müsste nach dem Fragezeichen ein Zeichen kommen, womit z.B. die Telefonnummern getrennt werden (wenn das aber immer der Fall ist). Andernfalls wird das Fragezeichen bei einem erfassten Zeichen aufhören.
In der Praxis ist dieses Muster ein wichtiges Werkzeug für präzise Textextraktionen, besonders wenn der gesuchte Text von bekannten Begrenzern umgeben ist, sodass der Beginn bzw. das Ende definiert werden kann.
Ich hoffe, für die Jenigen, die Regex für Magie gehalten haben, scheint der Prozess nicht mehr so kompliziert. Aber sobald man damit etwas herumspielt, merkt man schnell, dass es eigentlich total logisch ist und Spaß machen kann.