


Web scraping is a technique used to extract useful information from websites programmatically. It involves retrieving information from web pages by making HTTP requests to the web server, downloading the HTML content of the web page, and then parsing and extracting the desired information from that content. This data can be in the form of text, images, links, and more.
Note that web scraping is not APIs but similar. However the data we extracted in web scraping is less structure compared with APIs.
How do we do web scraping on Alteryx Designer?
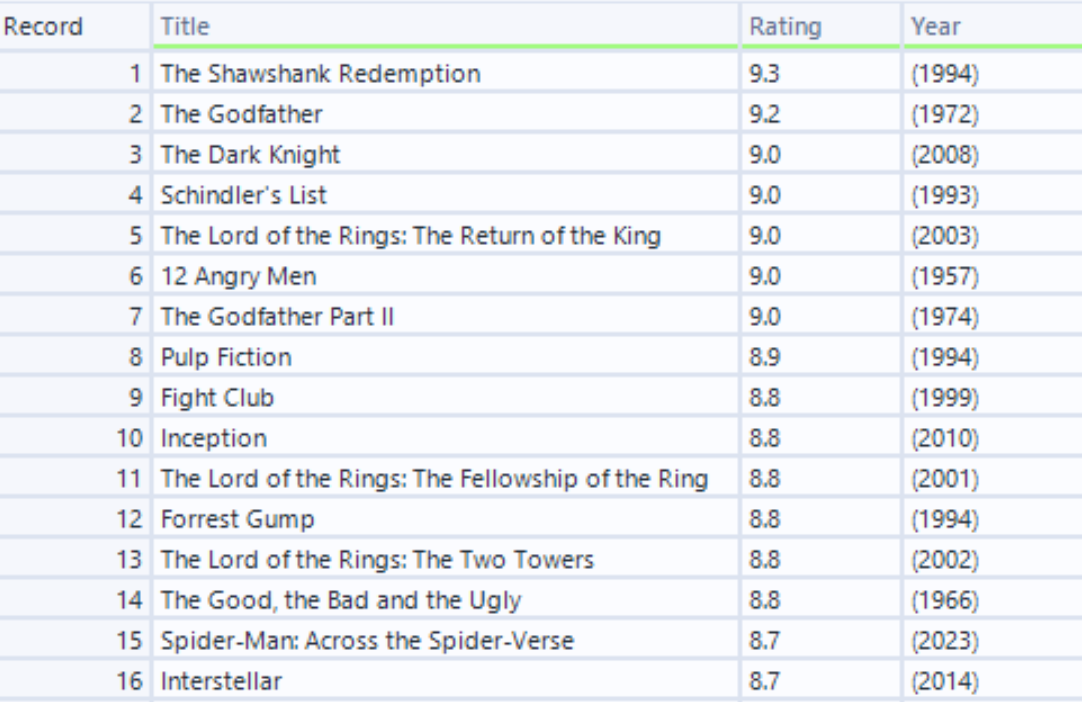
In my plan, I wanted to extract the Movie Title, Rating and Year from the link below:

This is how it looks like at the end:
To achieve this, we need to copy the URL in the text input tool. After downloading the data, we now have the HTML data in ther Alteryx.
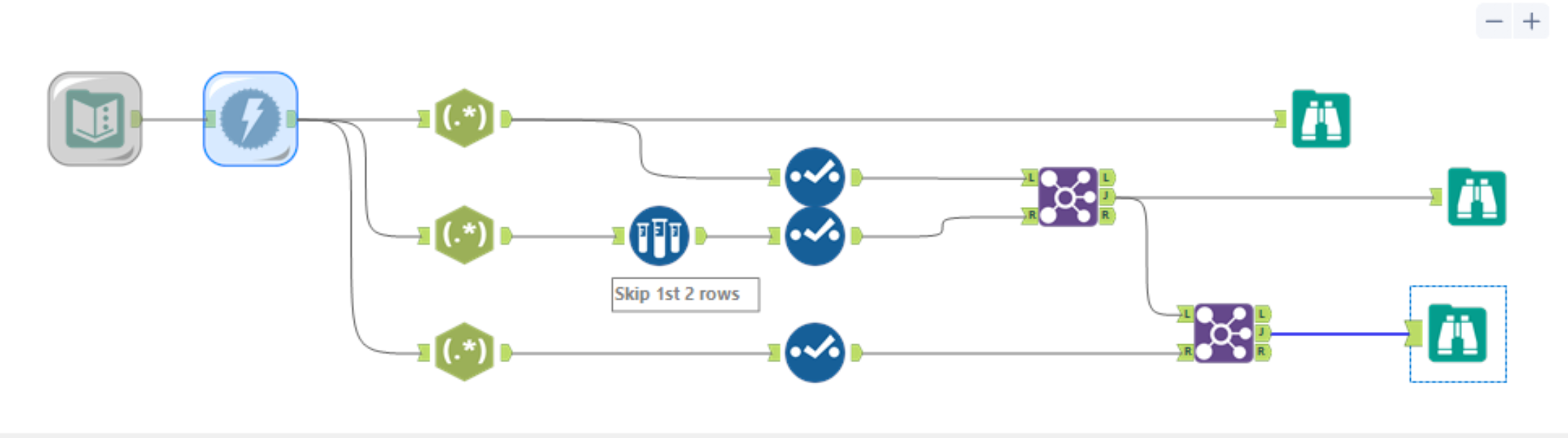
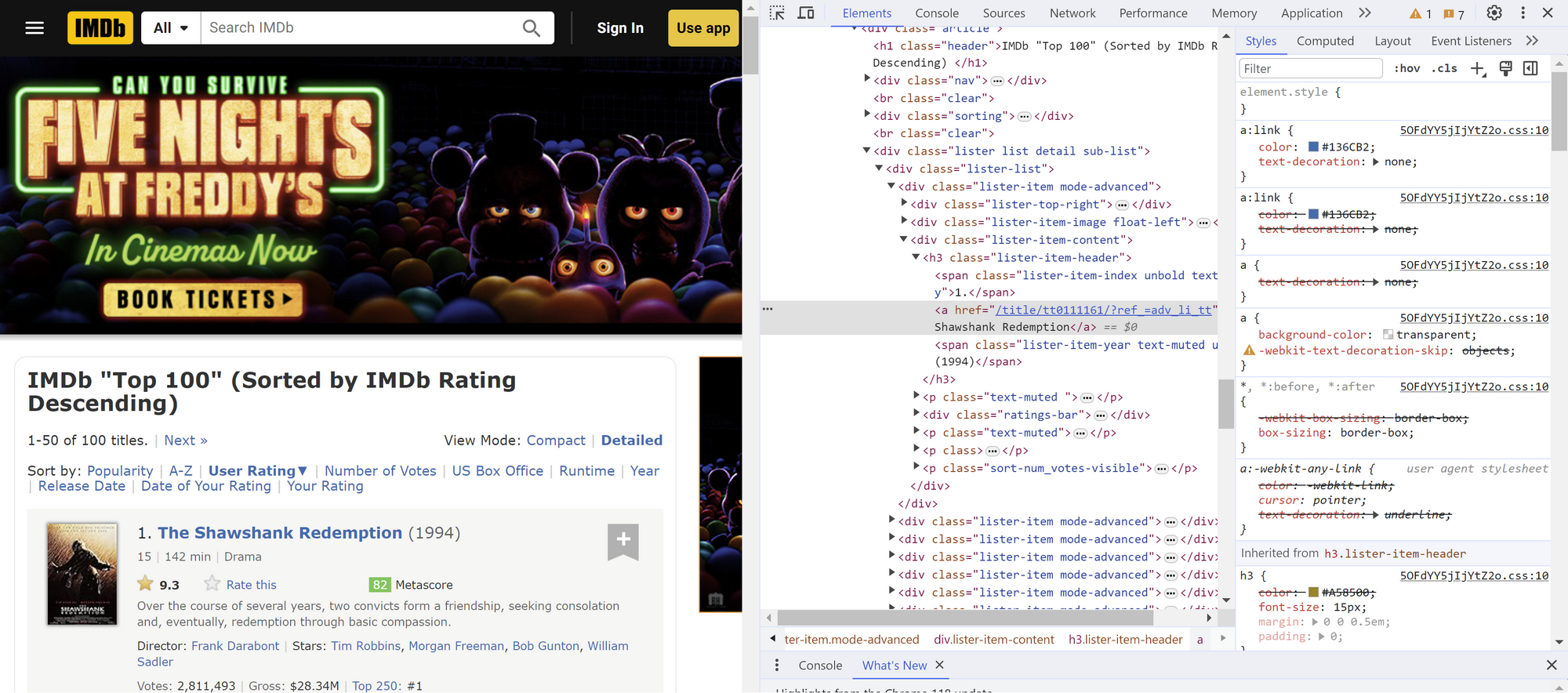
Next step is to extract the Movie Title from the HTML code. We can identify the code by opening an inspect window from the website. Click the top left arrow in the inspect window and hover over the mouse to the Movie Title, the specific HTML code for the Movie Title will then be highlighted in the inspect window for us:
Copy the code and use ReGex tool to extract the title. I put (.*?) in Regex expression which allows me to extract only the title from the HTML.
To extract the Rating and Year, it was like repeating the same flow but with slightly different on the Regex expression.
By joining the fields by position after extracting the Movie Title, Rating and Year, we can get the result we wanted at the end.