Last time we discussed APIs, and what can be gained through using them. But what do you do if a website has no API? Don’t panic! You can just download the HTML from the site itself. Not as bad as it sounds, trust me.
Before you start scraping a website, the first thing you need to do is check the Terms of Service of the website you want to scrape. Not all websites want you to have access to their data, and if you do so without their permission then you might end up in a bit of hot water. Some websites will allow you to scrape them depending on what you’re using the data for: if you want it for commercial use then this might be another no-no. It’s best to be sure before you start downloading a whole load of data you’re not supposed to.
Once you’ve checked and you’re sure you’re allowed, then you can set about thinking about the website itself. What you’ll be doing with web-scraping is extracting the HTML that you see when you access the web site. It won’t look pretty, because you won’t get the CSS, and it won’t move around because you won’t get the JavaScript. With Alteryx, it’s super easy to do this, and all you need is the URL and the download tool.
The hard work starts when you then try to parse out which parts of the HTML are relevant to your project, i.e. which <tags> hold the information you want to put into columns. As you can see from the workflow below, it takes a lot more to parse out than to download.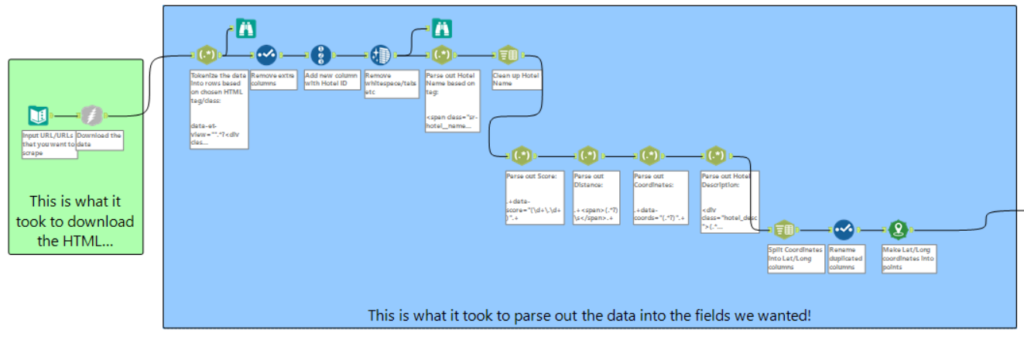
The way to work out which parts of the HTML you want is by inspecting the page. Different browsers might call this different things, but if you right click and choose Inspect/Inspect Element/similar then something like the following should come up:
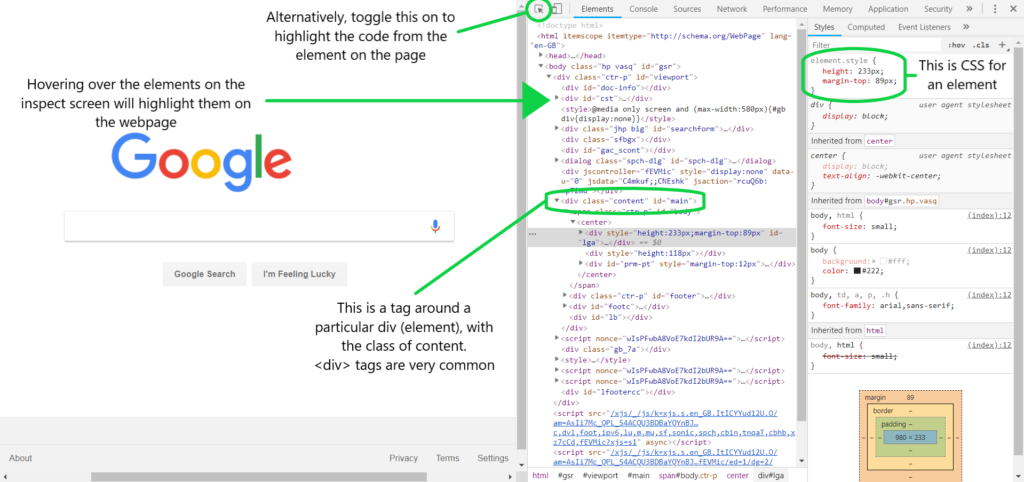
Once you’ve got the inspect tool up, you can search by hovering over the code itself in the inspect panel, which will highlight the elements on the page. Alternatively, toggle on the “highlight” button so that when you hover over the parts of the page you want, the corresponding code will be highlighted. Sometimes you might find little nuggets in the code from the developers, here’s a job opportunity we spotted:
When you’ve worked out which tags contain your information, use RegEx to parse out the data that sits between them. You might have to do a bit more cleaning, but you should now have the information you wanted…and there’s your first web scrape! You will probably find when you parse out a specific tag that it brings through other information you didn’t want. Expanding your RegEx to include the class or id of elements will help you narrow it down. You could also use just the class identifier, or really anything else that is unique to the piece of HTML you want.
The Price Problem
As I mentioned way back in Part I, if a website loads dynamically, then it will not be possible to scrape it using Alteryx without getting into some coding. As that is beyond the scope of this blog, we’ll stick to “dynamic websites can’t be scraped”. This is a problem Gheorghie and I had during a web-scraping project set for us by Ben, when we were unable to extract the price from the booking.com website.
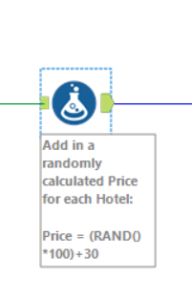 Our solution on the day, in the interests of time, was to add in a randomly calculated price for each hotel with a formula tool. This allowed us to output a complete data set and produce a simple viz, even if the price was not technically accurate. Sometimes, one of the lessons in the DS involves correctly scoping a project, and a proof of concept delivered in time might be better than a perfectly completed piece of work delivered late (that’s what I’ll tell myself anyway!). Our rudimentary output can be seen here.
Our solution on the day, in the interests of time, was to add in a randomly calculated price for each hotel with a formula tool. This allowed us to output a complete data set and produce a simple viz, even if the price was not technically accurate. Sometimes, one of the lessons in the DS involves correctly scoping a project, and a proof of concept delivered in time might be better than a perfectly completed piece of work delivered late (that’s what I’ll tell myself anyway!). Our rudimentary output can be seen here.
Thankfully, Andre and Robbin were around to help solve the mystery of the missing prices. It turns out the prices on the website are loaded asynchronously. What that means is that the price information is loaded after the rest of the HTML, so updates automatically if anything changes: full explanation of the how and why here. This allows the website to respond to requests which may be generated by other users, so in this example if someone else books a hotel and it becomes sold out.
When Alteryx downloads the data, it does so too quickly for the asynchronous data to load, hence why price is not brought through into the final dataset. To overcome this, Robbin added the browser to the Headers section. This opens to website on Chrome in the background, allowing the website to fully load before Alteryx downloads the data.
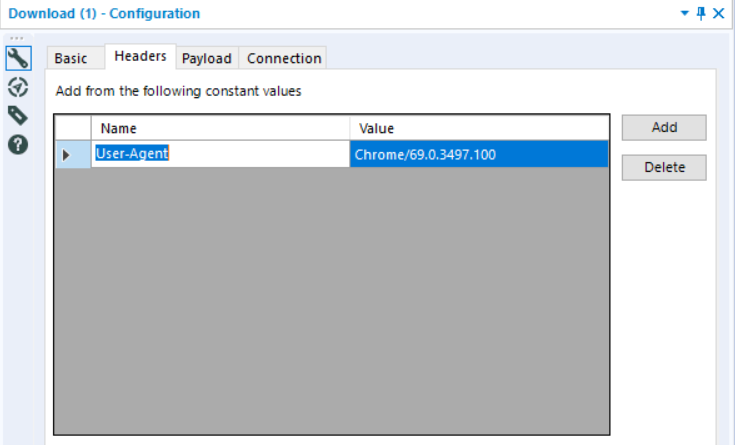
Configuring the Headers section in the download tool
And so the trilogy ends! Hope it’s helped in getting started with either or both, any questions let me know.
