Wednesdays session with Oliver was both interesting and frustrating, as we tried to wrap our heads around Regex. After endless examples involving Bob the Cat, I felt like I had a decent understanding but would still come unstuck when doing examples. The weekly challenge I chose to take on for Regex was challenge 13, which asked us to extract name/value pairs from a HTML table. The first step I took to complete this challenge was to look at the data I was dealing with and look for any patterns that might help me extract what i want using Regex. I did this using Sublime text.
Tokenize
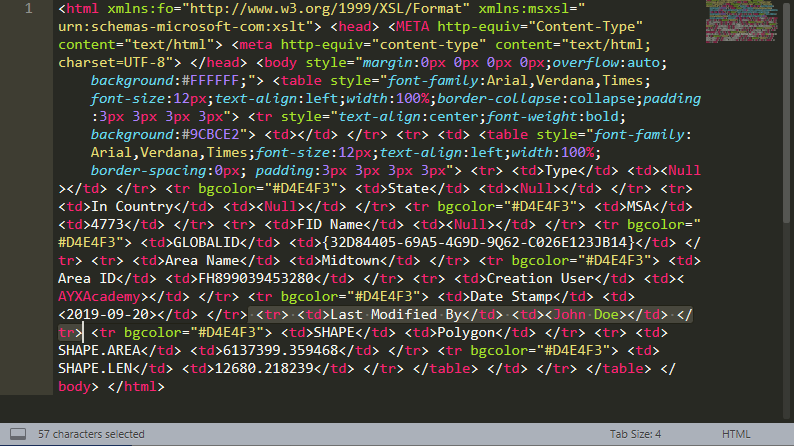
Now that a pattern had been identified, it was time to try and separate the 14 name/value pairs. To do this I used the Regex tool with the output method set to Tokenize and split to rows. This ensured that each piece of data with a different name/value pair were in separate rows.
The expression used to do this tells Alteryx to find expressions in the form <tr> <td>.+?<td> <td>.+?<td> <tr>, where ‘.’ is a wildcard, meaning it can be anything, ‘+’ indicates there is 1 or more wildcards, and the ‘?’ tells it to match as few as possible so that each pair is identified as a separate match.
Parse
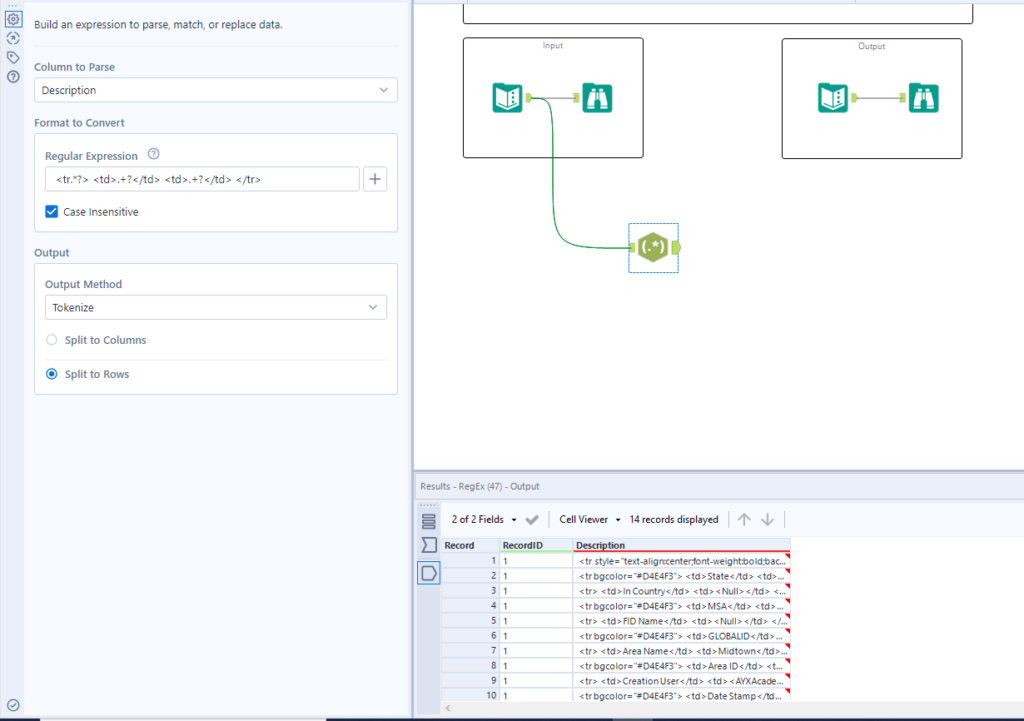
We now need to parse out the name/value pairs from the data we have tokenised. Again we do this using the regex tool, however this time we are using parse as the output method.
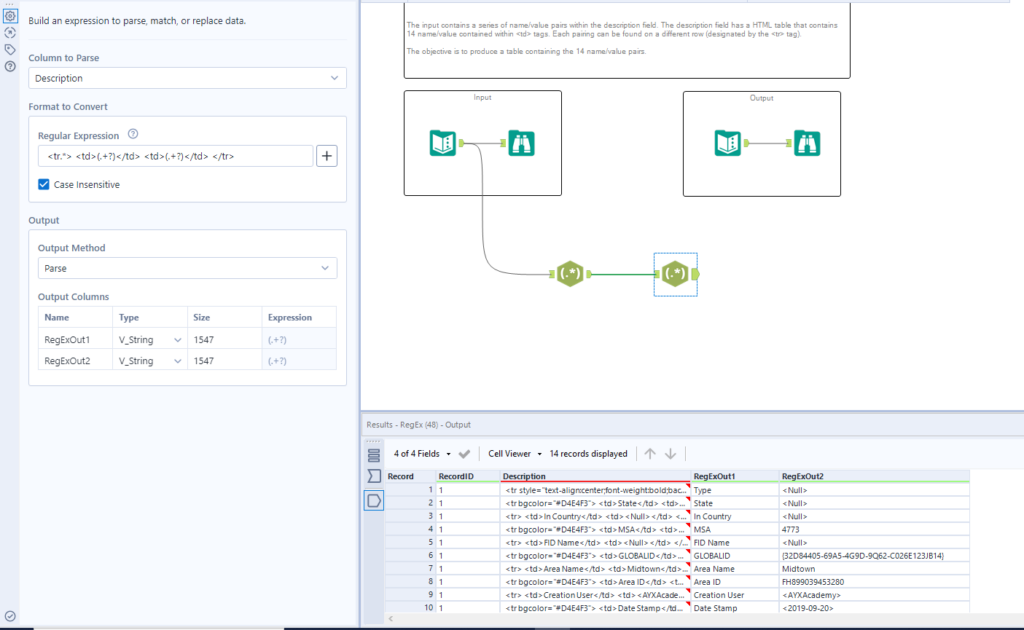
We are using the same expression as before, however this time we are encasing the .*? in brackets because this is the part of the expression we want to parse out.
Clean
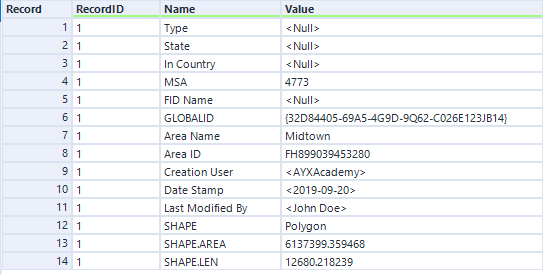
That’s it! All that’s left to do is tidy up our output with a select tool, and we are left with the output shown below:
If there is one thing I have learnt in my first few days of using Regex, which Chris reinforced yesterday, its if in doubt, use (.*?)!
