


In our first week at the Data School, we learnt that before any kind of data analysis it’s important to understand what type of data you have, and if you need to do some data prep. Data can be categorised as either clean or dirty data.
Clean data can be defined by 4 rules:
- One data field for each category or measure
- One data type for each data field
- A single date column where possible (exception)
- One row should be an occurrence containing all values of each data field (if possible)
Here's an example of clean data based on DS43's coffee preferences:
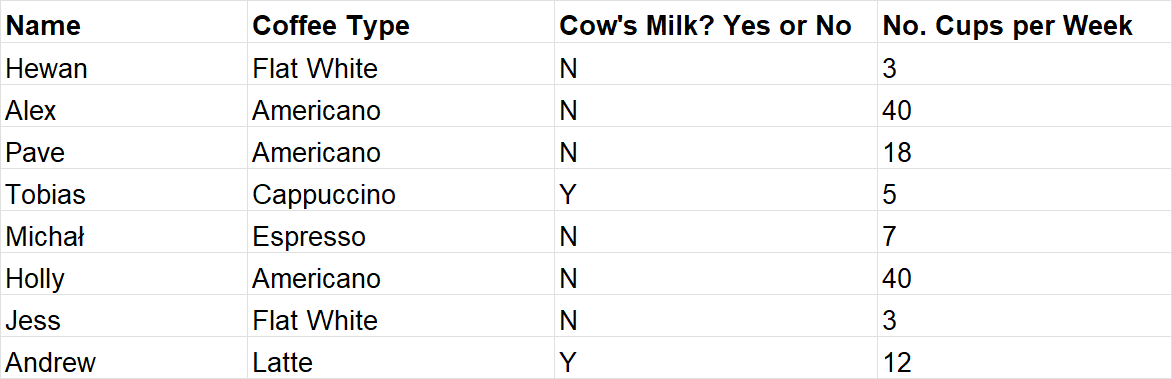
Dirty data can be defined as:
- Anything that breaks the ‘rules’ of data structure (e.g. multiple data points pushed into a single field, single occurrences split across multiple rows, typos, and missing headers)
- Out of date data
- Missing values (however sometimes they’re needed!)
Here's an example:
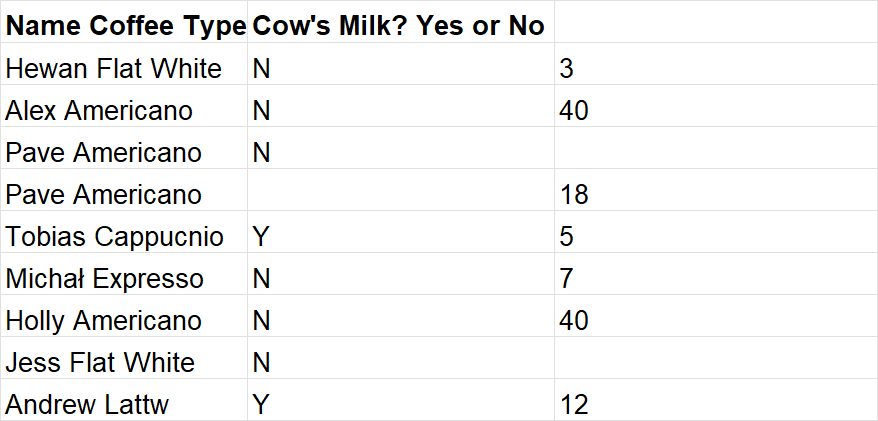
If you find that your data is dirty, proper steps need to be taken to make sure it follows the 4 rules of clean data for more efficient and accurate data analysis and interpretation.